資料探勘(Data Mining) 概念是什麼?
Content
1.瞭解分類Classification的概念
2.學習簡單的分類演算法
- 決策樹
- 最鄰近法
- 簡單貝氏分類(機率)
瞭解分類classification的概念
Def:將一個物件指定預先定義的分類
以性別分類為例,某一些名字一定是男生,某一些名字一定是女生。
- 分類就是在做"貼標籤"labeling的過程。
- 分類模型,可以幫助"做預測"prediction。
- 重要
- 一般
- 垃圾
數學Def:建立一個學習函數(分類模型)將每個屬性集合(x)分類到一個以定義的類別y
(想成一個黑盒子,輸入x,輸出y)
(標題、寄件者、內文、寄件時間)→黑盒子→重要、一般、垃圾
如何建立分類模型?(分辨奧客)
舉例:先train好客人,在train壞客人,發現好客人會穿西裝、鼻孔大,壞客人會舉手、眉毛粗...
訓練資料→(歸納)→學習演算法+學習模型→模型→應用模型→(推論)→測試資料
延伸問題:哪個模型比較好?

找了一張類似的圖,這個是用KNN
分類演算法的核心問題
- 支援向量機Support Vector Machine(SVM):找一條線可以切割
- 類神經網路Artificial Neural Network(ANN):模擬人類的思維做分類
- 最鄰近法K-Nearest Neighbor(KNN):以一個半徑,劃一個圈,看誰數量多
- 決策樹(Decision Tree):切割方法(直線與橫線),很像遞迴
- 簡單貝氏分類法(Naive Bayes Classifier):虛線十字,算比例
混淆矩陣(Confusion Matrix)
計算模型的正確率,預測的優劣(老師特別強調)
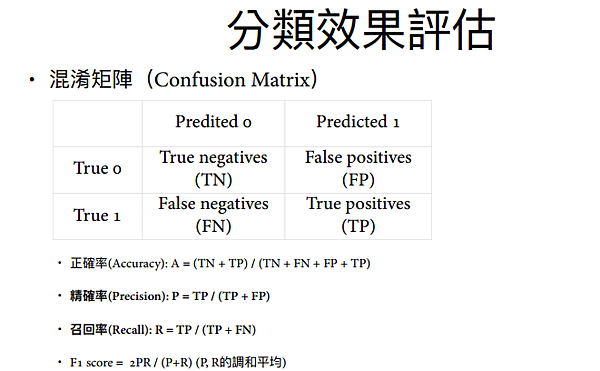
分別有預測類別、實際類別,算出正確率、錯誤率
學習簡單的分類演算法
- 訓練資料(建立模型用75%)
- 鑑效資料(驗證模型用,建立模型中)
- 檢驗資料(測量模型用,建立模型後25%)
什麼是決策樹?

根節點、內部節點、葉節點(考點)
概念:回歸分割
切割完剩同一類,就停了
切割完剩同一類,就停了
屬性的條件可以有幾個分支?
- 二元屬性(是/否、男/女,恰好可以轉換成兩個分支條件)
- 類別屬性(血型、隊名,多個也可以分為兩個分支條件)
- 順序屬性(學歷、等級,依照順序併,但不要跳脫順序!)
- 連續變數(身高、體重、薪資,做切割,過度將連續型資料切割會變成overfitting)
選擇哪個屬性來分割比較好?
分類的結果越乾淨越好
延伸問題:如何描述乾淨(混亂)的程度?
畫一張亂度表
亂度衡量指標
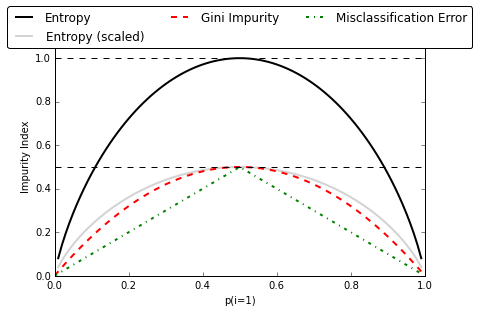
- Entropy
- Gini
- Misclassification Error
有了亂度的衡量要如何選擇?
求出information gain
屬性分支樹與Gain的關係
→避免"overfitting"過度配適
(為了少數的資料製造過度複雜的模型)
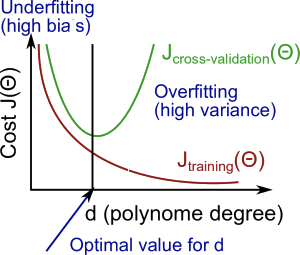
距離怎麼算?
如何避免過度配適?
- 事先修剪(Pre-puning)
- 事後修剪(Post-puning)
如何使用最鄰近法?
概念:物以類聚距離怎麼算?
- 歐式距離
- 曼哈頓距離

沒有留言:
張貼留言