先說因為最近在參加一些KAGGLE比賽,看看各位大大們都是用lgb或是xgb來跑,認真研究了一下,整理一下結論,文章出爐啦!!!
如果想更了解LightGBM,可以看我的LightGBM explained系列文:
- LightGBM + GridSearchCV 調整參數(調參)feat. Categorical Data處理
- LightGBM explained系列——Histogram-based algorithm是什麼?
- LightGBM explained系列——Exclusive Feature Bundling(EFB)是什麼?
- LightGBM explained系列——Gradient-based One-Side Sampling(GOSS)是什麼?
LightGBM(lgb)
首先,大家會問LightGBM是什麼?
其實是進階版的Decision Tree,只是它的分枝是採用Leaf-wise(best-first),而不是傳統的Level-wise(depth-first)。
Optimization in Accuracy
以下簡單介紹一下(大家都會介紹):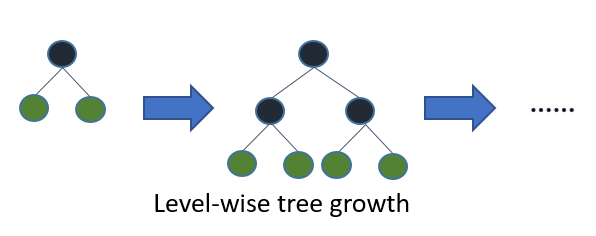 |
| https://lightgbm.readthedocs.io/en/latest/Features.html |
Level-wise會每一層每一層建立整個tree,屬於低效率的方式。
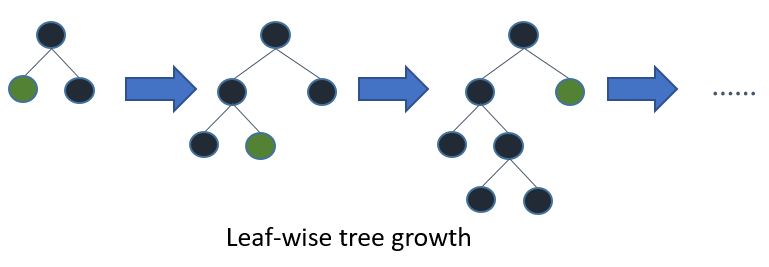 |
| https://lightgbm.readthedocs.io/en/latest/Features.html |
Leaf-wise則是針對the leaf with max delta loss to grow,所以相對於每一層每一層,它會找一枝持續長下去。要小心的是在data比較少的時候,會有overfitting的狀況,不能讓它一直長下去,所以可以用max_depth做一些限制。
所以大家要想像一下,在巨量資料的狀況下,因為LightGBM可以以一個更快、更有效的訓練方式,達到一定的準確率,所以大家才比較喜歡用它
註:剛剛看到一個蠻重要的順便附上來!
Optimal Split for Categorical Features
常常碰到Categorical Data =類別型資料,最常出現的整理(變成數值)的方法,有三種:(順便整理一下目前知道的方法)- LabelEncoder(le)例如:把"性別"欄位的男跟女改成0跟1
例如:把"星期"欄位改成1, 2, 3, 4, 5, 6, 7 - OneHotEncoder(ohe) / dummy variables
例如:把一欄"性別"欄位的男跟女改成兩欄"男"跟"女"(值分別是0跟1) - Feature hashing (a.k.a the hashing trick)
很像OHE但降低維度
除此之外,lgb還提供
- input設置 categorical_feature= 0, 1, 2(第一欄從位置0開始) or name: c1, c2, c3(直接指col名稱)
- parameter設定 min_data_per_group / max_cat_threshold / cat_l2 / cat_smooth等
綜上所述,lgb會依據每個categorical feature的accumulated values (sum_gradient / sum_hessian) 找到最佳的分支點。而且重點是這是內建的,不需要再進行而外的0跟1的展開。
- Categorical features只支援到Int32.MaxValue (2147483647),小心別溢位了!
- convert your categorical features to int type before you construct Dataset.
- 所有negitive的值會被當作missing value
Therefore, (感覺講了太多前情提要不太妙...)
直接進入code順便之講解一下基本的理解:
https://github.com/Microsoft/LightGBM/blob/master/examples/python-guide/simple_example.py#載入套件
import lightgbm as lgb
#載入train和test data(依據每份資料不同)
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
#將資料分為
y_train = train['train要比對預測的欄位']
y_test = test['test要進行預測的欄位']
X_train = train['train要進行訓練的參數']
X_test = test['test要用來進行預測的參數']
⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺
#產生lgb的dataset
lgb_train = lgb.Dataset(X_train, y_train) #要進行訓練的
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train) #要進行驗證的
# 需要先建立好自己parameter的dictionary
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': {'l2', 'l1'},
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
#核心參數Core Parameters
'''boosting_type:通常會用traditional Gradient Boosting Decision Tree(聽說比較經典),還有 'rf'(random_forest) 等
objective:指的是任務目標,有分 'regression', 'binary' 等分很細的多樣種類
num_leaves:設定一棵樹最多幾片葉子(葉節點),預設是31片,不管如何一定要大於1
learning_rate:讓我想到老師上課的時候說的eta(shrinkage rate),專業一點叫每次梯度下降的幅度,簡單一點可以說是你要你的樹成長多快。
註:一般都會設置0.2~0.5之間
'''
#學習控制參數Learning Control Parameters
'''max_depth: 一開始有提到,限制樹的深度
註:照理說num_leaves <= 2^(max_depth)
feature_fraction:可以用來對付overfitting以及加快訓練速度,必須介於0跟1之間,每回合隨機選擇 "百分比 of features"(部分特徵,而非全部),來形成樹
下面bagging兩兄弟,絕不輕易分離↓
bagging_fraction:功能跟feature_fraction相似,但選擇時是without resampling(不重新採樣)
註:要進一步設置bagging_freq > 0
bagging_freq:0 表示不啟用bagging,k 表示在每k回合後 perform bagging
lambda_l1: L1正則化 > 0 (可能之後再寫關於這是什麼)
lambda_l2: L2正則化 > 0
cat_smooth: 專門for Categorical Data,減少 the effect of noises噪音
'''
#測量參數Metric Parameters
'''metric:metric(s) to be evaluated on the evaluation set(s),也就是在驗證的時候的loss function,一些經典的像是 'l1'(mean_absolute_error), 'l2'(mean_squared_error), 'l2_root'(rmse) 等
註:如果填入'',會依據objective自動做出判斷
'''
#IO Parameters(還認真不知道中文)
'''verbose:verbose這個字有冗長的意思,預設是1 (info),通常看到的都是 0 Error (Warning)
註:後來發現是日誌的顯示,可以看lgb training的過程
'''
#還有一些參數例如:valid(test data), num_threads(CPU), min_data_in_leaf(overfitting), max_bin(max number of bins that feature values will be bucketed in)都是一些有機會用到的參數
#訓練模型
gbm = lgb.train(params,
lgb_train,
num_boost_round=預設100, #number of boosting iterations
valid=lgb_eval,
early_stopping_rounds=預設0) #當valid中的一個metric沒有improve則停止訓練
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration) #number of boosting iterations
#評估
from sklearn.metrics import mean_squared_error
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
GridSearchCV 調整參數(調參)
當然很多時候,到底個參數調什麼?多少?會是很大的問題這時候就要運用sklearn裡面的GridSearchCV,但在那之前......
https://github.com/Microsoft/LightGBM/blob/master/examples/python-guide/sklearn_example.py
先介紹sklearn的版本:
⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺#箭頭前都相同
#訓練模型
gbm = lgb.LGBMRegressor(num_leaves=31,
learning_rate=0.05,
n_estimators=20)
#注意LGBMRegressor是regression的狀況,今天如果是classification,則改用LGBMClassifier
gbm.fit(X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='l1',
early_stopping_rounds=5)
#預測
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
正式GridSearchCV:
⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺⟺#箭頭前都相同
#載入套件
#from sklearn.grid_search import GridSearchCV 這是舊版的,請用下面新版的
from sklearn.model_selection import GridSearchCV
#跟剛剛的類似,先設好一個所使用的分類器
estimator = lgb.LGBMRegressor(num_leaves=31)
#比較少的版本
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
#非常多的版本(當然要自己斟酌)
parameters = {
'max_depth': [15, 20, 25, 30, 35],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'feature_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 0.95],
'bagging_freq': [2, 4, 5, 6, 8],
'lambda_l1': [0, 0.1, 0.4, 0.5, 0.6],
'lambda_l2': [0, 10, 15, 35, 40],
'cat_smooth': [1, 10, 15, 20, 35]
}
#使用GridSearchCV
gbm = GridSearchCV(estimator, param_grid, cv=3)
#放入model跟參數,注意的是cv(交叉驗證參數)通常設3
#也可以放入其他參數,scoring有Classification, Clustering, Regression三大類
#https://scikit-learn.org/stable/modules/model_evaluation.html
gbm.fit(X_train, y_train)
#print出最佳參數(調參結果)
print('Best parameters found by grid search are:', gbm.best_params_)
20181231後記:調參我後來發現不能一次到位(除非設備到位$$$),不然應該採用循序漸進的方法
sklearn-GridSearchCV,CV调节超参使用方法
XGBoost和LightGBM的参数以及调参
当GridSearch遇上XGBoost 一段代码解决调参问题
Decision trees: leaf-wise (best-first) and level-wise tree traverse
gbm.fit(X_train, y_train)
#print出最佳參數(調參結果)
print('Best parameters found by grid search are:', gbm.best_params_)
- 先把最基本的'boosting_type', 'objective', 'metric'設定完成,再把其他parameters估計一下
- 從max_depth, num_leaves下手找到兩個的perfect match
- 對min_data_in_leaf, min_sum_hessian_in_leaf下手
- 來到feature_fraction, bagging_fraction
- 正則化兩位lambda_l1, lambda_l2
- 最後learning_rate(eta)下手
參考文獻:
gridSearchCV(网格搜索)的参数、方法及示例sklearn-GridSearchCV,CV调节超参使用方法
XGBoost和LightGBM的参数以及调参
当GridSearch遇上XGBoost 一段代码解决调参问题
Decision trees: leaf-wise (best-first) and level-wise tree traverse

沒有留言:
張貼留言